
Welcome to my blog! In today’s article, we’ll explore the question, “Is KNN Algorithm Supervised or Unsupervised?” Dive into the world of algorithms and discover the key differences between these learning techniques.
KNN Algorithm: Exploring Supervised or Unsupervised Learning in the World of Algorithms
The KNN Algorithm, also known as the K-Nearest Neighbors Algorithm, is a popular and versatile method in the world of algorithms, which can be applied to various types of problems. By understanding its nature, we can classify it as a form of Supervised or Unsupervised Learning.
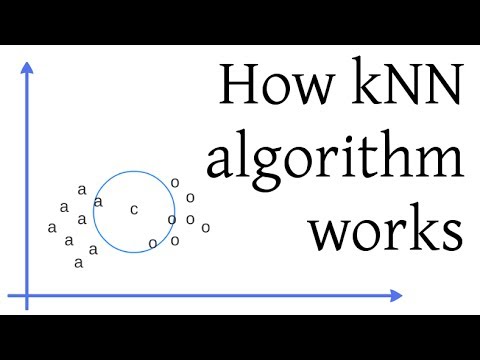
KNN is primarily a classification algorithm, which means it is used to assign a label or category to a new data point based on its features. The algorithm works by considering the k-nearest neighbors of the new data point, which are the k data points that are closest to it in terms of a specified distance metric. The most common distance metric used in KNN is the Euclidean distance, although other metrics like Manhattan distance can also be used.
To determine the classification of the new data point, the algorithm looks at the labels of the k-nearest neighbors and selects the label with the highest frequency among them. In the case of a tie, different strategies can be employed such as selecting the label with the shortest average distance to the new data point.
The KNN algorithm can be classified as a form of Supervised Learning, as it requires a labeled dataset to train the model. The labeled dataset is used to identify the k-nearest neighbors and their respective labels, which are then used to classify new data points. This is in contrast to Unsupervised Learning, which does not require any labeled data and aims to discover underlying patterns or structures within a dataset.
However, KNN can also be adapted to perform Unsupervised Learning tasks such as clustering, where the goal is to group similar data points together without any prior knowledge of their labels. In this scenario, KNN can be used as a similarity metric to identify the most similar data points, and then cluster them together accordingly.
In summary, the KNN Algorithm is a powerful and flexible method that can be used for both Supervised and Unsupervised Learning tasks in the world of algorithms. Its classification and clustering capabilities make it a highly valuable tool for solving various challenges in data analysis and machine learning.
How kNN algorithm works
K – Nearest Neighbors – KNN Fun and Easy Machine Learning

Is it possible to employ KNN for unsupervised learning?
Yes, it is possible to employ K-Nearest Neighbors (KNN) for unsupervised learning. Although KNN is majorly known as a supervised learning algorithm, it can be adapted for unsupervised learning tasks such as clustering.
In unsupervised learning using KNN, the goal is to find patterns and relationships in the input data. A popular method for this is k-Means clustering, where the data is partitioned into ‘k’ clusters, with each cluster having its own centroid. The algorithm iteratively refines the centroids and reassigns data points to the nearest centroid until a stopping condition is met.
Using KNN for clustering, data points are considered as nodes in a graph, and edges are created between the k-nearest neighbors. Clustering can then be performed using techniques such as the Connected Components Labeling algorithm, which groups connected nodes in the graph into separate clusters.
Therefore, KNN can indeed be employed for unsupervised learning tasks such as clustering and discovering underlying structures within unlabelled data.
Is KNN a kind of unsupervised algorithm – True or False?
False. KNN, which stands for K-Nearest Neighbors, is a type of supervised learning algorithm. In the context of algorithms, KNN is used for both classification and regression tasks, relying on labeled data to make predictions.
Is K-Nearest Neighbors clustering a supervised learning method?
The K-Nearest Neighbors (KNN) algorithm is a type of supervised learning method, primarily used for classification and regression tasks. In the context of algorithms, KNN relies on the labelled data to make predictions for new, unseen instances based on the similarities between the features of the input data and the features of the labeled data.
What distinguishes KMeans from KNN in terms of their algorithms?
In the context of algorithms, KMeans and KNN are two distinct machine learning techniques that serve different purposes. Here are the key differences between them:
1. Purpose: KMeans is an unsupervised learning algorithm used for clustering while KNN is a supervised learning algorithm used for classification and regression.
2. Algorithm: The KMeans algorithm iteratively finds centroids of clusters and assigns data points to the nearest centroid. In contrast, KNN estimates values or classifies new data points based on the majority vote from its K-nearest neighbors.
3. Training: KMeans involves a training phase where centroids are determined, whereas KNN has no explicit training step and works based on the existing dataset.
4. Output: The output of KMeans is a set of cluster centroids and the data points associated with each centroid, while the output of KNN is the predicted class or value for the input data point.
5. Model complexity: KMeans usually deals with a fixed number of clusters (K), whereas KNN’s model complexity depends on the number of neighbors (K) and distance metric used.
In summary, KMeans is an unsupervised clustering algorithm, while KNN is a supervised learning algorithm for classification and regression. They differ in terms of purpose, algorithm, training, output, and model complexity.
What distinguishes the KNN algorithm as a supervised or unsupervised learning method within the context of algorithms?
In the context of algorithms, the K-Nearest Neighbors (KNN) algorithm is primarily known as a supervised learning method. This is because it requires labeled data for training in order to make predictions on new, unseen data points.
The main characteristic that distinguishes supervised learning from unsupervised learning is the presence of labeled data. In supervised learning, the model learns from a dataset with known outputs or target variables, whereas in unsupervised learning, the model works with a dataset without any labels or target variables, aiming to identify inherent patterns or structures within the data.
In the case of KNN, the algorithm uses the similarity between feature vectors of the training data points and a new data point to determine its output. It looks for the k-nearest neighbors in the training set, and then assigns the new data point to the class that is most prevalent among these neighbors. This process relies on the availability of labeled training data to make predictions, which is why KNN is considered a supervised learning method.
How does the classification process in the KNN algorithm reveal its nature as a supervised or unsupervised learning technique?
The K-Nearest Neighbors (KNN) algorithm is a widely used machine learning technique that can be applied to both classification and regression tasks. It is an example of supervised learning, as it uses labeled training data to classify new, unlabeled instances.
In the KNN algorithm, the classification process consists of the following steps:
1. Calculate distances between the new instance and all other instances in the training data.
2. Select K nearest neighbors by finding the K instances that have the smallest distances to the new instance.
3. Majority vote: Determine the class of the new instance by checking which class has the highest frequency among its K nearest neighbors.
The reason why KNN is considered a supervised learning technique is that it relies on labeled training data to make predictions. During the majority vote step, the algorithm looks at the class labels of the K nearest neighbors, which were provided during training, to determine the class of the new instance.
In contrast, unsupervised learning techniques do not use labeled data; they only work with the input features to discover patterns, groupings, or relationships within the data. As the KNN algorithm relies on the labeled samples from the training dataset for classification, it reveals its nature as a supervised learning technique.
Can you provide examples of how the KNN algorithm is utilized in both supervised and unsupervised contexts, if applicable?
The k-Nearest Neighbors (KNN) algorithm is a versatile machine learning technique that can be applied to both supervised and unsupervised learning problems. In its core, KNN works by looking at the ‘k’ nearest data points to a given input and making predictions or decisions based on their labels or features.
Supervised Learning with KNN
In supervised learning, the KNN algorithm is used for classification and regression tasks. The primary idea behind these applications is that similar data points are likely to share similar labels or target values.
1. *Classification*: In a classification problem, the goal is to assign a class label to a new data point based on the majority class of its k nearest neighbors. For example, if you have a dataset of patients with and without a certain disease, KNN can predict whether a new patient has the disease by examining the diagnoses of the k closest patients in the dataset.
2. *Regression*: In a regression problem, the goal is to predict a continuous target value based on the average value of the k nearest neighbors. For example, if you have a dataset of houses with their features and selling prices, KNN can predict the price of a new house by taking the average of the k closest houses in the dataset.
Unsupervised Learning with KNN
In unsupervised learning, KNN can be utilized for tasks such as clustering and anomaly detection, where the primary aim is to reveal hidden patterns within the data without prior knowledge of the target variable.
1. *Clustering*: Clustering is the process of grouping similar data points together based on their features. The KNN algorithm can be applied in clustering by calculating the distance between each pair of data points, then linking the nearest neighbors together, and finally assigning each group a unique cluster label. One popular clustering method using KNN is the DBSCAN algorithm.
2. *Anomaly Detection*: Anomaly detection’s goal is to identify abnormal data points that differ significantly from the majority of the dataset. In a KNN-based anomaly detection approach, a data point is considered an outlier if its distance to its k nearest neighbors exceeds a predefined threshold.
In summary, the k-Nearest Neighbors algorithm is a powerful and versatile machine learning technique that can be applied in both supervised (classification and regression) and unsupervised (clustering and anomaly detection) contexts.

